Free Software programmer
rusty@rustcorp.com.au
Subscribe
Subscribe to a syndicated
feed of my weblog, brought to you by the wonders of
RSS.
This blog existed before my current employment, and obviously reflects my own opinions and not theirs.

This work is licensed under a Creative Commons Attribution 2.1 Australia License.
Categories of this blog:
IP issues
Technical issues
Personal issues
Restaurants
Older issues:
All 2008 posts
All 2007 posts
All 2006 posts
All 2005 posts
All 2004 posts
Older posts

Sun, 09 Nov 2008
Ccan gets some much-needed love
OK, so CCAN (think CPAN for C) finally got some cycles: the web page no longer completely sucks, and there's a rudimentry upload facility.
I thought it worth mentioning it here; IMHO it's something which would really advance best practices in C, but obviously needs a fair amount of more polish and a LOT more code before that becomes a reality. (The handful of modules so far are mine, most inspired by Linux kernel practice, such as the reimplemented list.h).
[/tech] permanent link
Mon, 01 Sep 2008
Welcome Arabella Lilly Russell, into a complex world
At 10:58am Adelaide time, on the first day of the Southern Hemisphere spring, Arabella was born as planned, 10 weeks premature and 1.06 kg (37 ounces). Pink and wiggly, and spending at least 6 weeks in hospital.
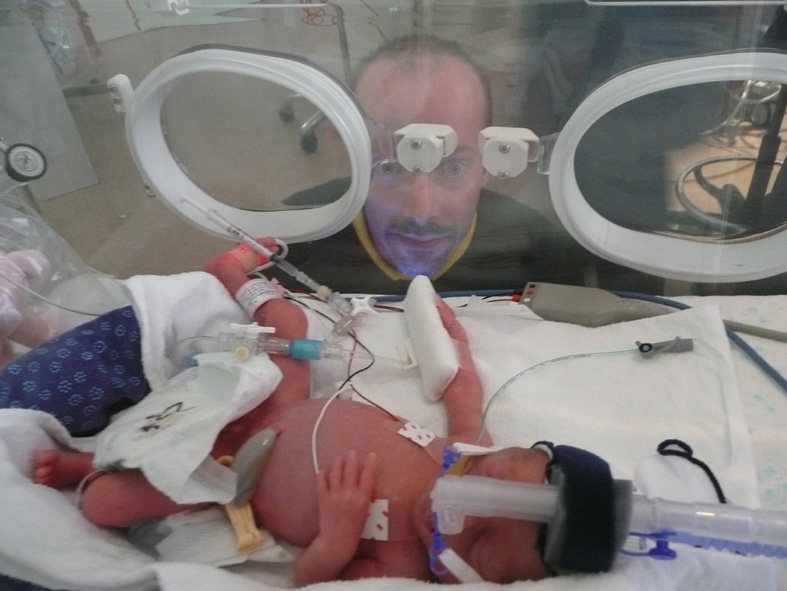
As some of you know, Alli and I are separated: she left me 3 months ago. I came to Adelaide for Arabella's birth, then I'm going back for a couple of weeks to pack up the farm, then returning to Adelaide because Arabella is here. I hope we manage to raise Arabella OK despite our split.
[/self] permanent link
Fri, 29 Aug 2008
Linux Next Graphing
Some neat stats just graphing the size of the bz2 patch for Linux next for the last 108 days (12 May through 28 August). Since Stephen doesn't produce patches on weekends, you can see the gaps (dashed lines are Mondays, Australian time)
The -rc1 dip is really clear (these patches are produced against the last labelled Linus kernel, so hence it's a one day drop), and you can see the -rc2, -rc3 and -rc4 dips diminishing like they're supposed to. Those sharp-eyed will note that during the merge window, kernel hackers work weekends :)
[/tech] permanent link
Sat, 16 Aug 2008
IMDB Top 250 By Year, With No Serious Statistical Method
In a moment of idle curiosity, I wondered whether there was really a "golden age" for cinema. Maybe the IMDB Top 250 could shed some light, despite an obvious preference for recent films?
I broke the stats into 5 year segments: 1920 means 1920 thru 1924 inclusive. For the 2005-2009 segment, I extrapolated by 1.4, since we're only 3 1/2 years through that.
First I looked at raw numbers. How many movies from each 5 year segment feature in the IMDB top 250? This tops with the 2005-2009 section (extrapolated to 42 movies):
But that makes #250 count the same as #1. So if we weight each one, such that #1 gets 250 points, #2 gets 249 points, and #250 gets 1 point:
So clearly, the 50s (eg. 1957's 12 Angry Men at #10) was one peak, around 1980 (eg. Star Wars trilogy in 1977, 1980 and 1983 at #12, #9 and #109), and another may have just passed us in 2000 (eg. Lord of the Rings trilogy in 2001, 2002 and 2003 at #20, #31 and #14).
[/self] permanent link
*sniff*

Tue, 22 Jul 2008
WTF? Wikipedia deletion gone mad...
OK, so Dave Miller's pending deletion I can understand; if you didn't know how key he was, the article itself lacks references and is lacks detail (compare it with Andrew Tridgell's page. (At least he noticed; when I was deleted last time I didn't know).
But then I find out that the article on OLS was deleted back in February. Huh? This is the major Linux conference in the world. Some would argue that it's a bit faded at the edged these days, but none of the crop of contenders can genuinely claim that crown. I know conferences don't generally get pages as sexy as humans do, but still...
[/tech] permanent link
Sun, 20 Jul 2008
The Joy of linux-next
Sure, linux-next is a useful way of early-detecting patch conflicts with random developers. But the second order effect has been more useful to me: forcing me to get my shit together. Now I regularly publish my patchqueue in a form which applies and compiles, and has clear "production" vs "alpha" demarcation.
Obviously, this is good for people trying to follow various patches (and there are quite a few independent efforts at the moment, including typesafe patches, virtio, lguest, module, tun/tap, stop_machine, kmod-removal and down_trylock removal), but it also makes the arrival of the merge window far less stressful.
In theory, I could have been this organized before. But just like the concept of doing homework long before the deadline, it was never going to happen. So thanks Stephen!
[/tech] permanent link
Mon, 14 Jul 2008
UNSW CS: Employment @ IBM OzLabs Talk: 1pm Tuesday September 2nd
UNSW School of Computer Science and Engineering are having "Employer of the Week" experiment: September 1st is IBM's week. I'll be spruking for OzLabs, so if you know anyone at UNSW who worth talking to, drag them there (I don't know which room, I'm guessing the signs in CS will be pretty clear).
I'm going to try to talk about the stuff people in the office are hacking on, to give an idea what it's like being in what AFAICT is Australia's largest bunch of Free and Open Source Software hackers.
[/tech] permanent link
Mon, 30 Jun 2008
stop_machine latency: the rewrite
Following on from my previous graphs of stop_machine latency, I have new results with my stop_machine simplification patch.
Again, it's the 18-way Power4 box; the simplied stop_machine creates all the threads and moves them into the correct CPUs before starting them. They then step through the state machine themselves, rather than having a central controller.
Since these are different kernel versions, I looked at the baseline latency for both kernels:
Now I need to go back and compare the exact same kernel version, to make sure something else isn't interfering...
[/tech] permanent link
Fri, 27 Jun 2008
Linux Foundation's Device Driver Statement
Someone noted that I didn't sign the LF "proprietary modules are bad" statement. This is entirely due to my slackness and not any lack of support.
As kernel module maintainer I feel obliged to maintain the status quo with proprietary modules, but I have noticed many colleagues becoming more annoyed about them.
[/tech] permanent link
Mon, 16 Jun 2008
Selling the Farm
 .
.
With Alli's high-risk pregnancy, we're selling the farm and moving back to an apartment in Adelaide (where both our families are). She's moved across already, I'm staying to take care of the farm until it sells.
Unfortunately farms do not sell quickly, but it gives me time to have everyone visit (again). And now we're selling, there's less chance you'll be asked to do random tree planting or similar chores.
When Richard Guy Briggs visited last year he took some great photos, and now seems a good chance to link to them.
[/self] permanent link
Thu, 12 Jun 2008
stop_machine latency
Kathy Staples and I wrote a little program to measure the latency on every CPU on a machine. It sets CPU affinity and high priority (SCHED_FIFO, prio 50) for each thread, then spins doing gettimeofday() for a given duration. The maximum gap in gettimeofday() is reported for each CPU.
I tested this on an old 18-way Power4 box sitting around the lab: CPU 0 is used for the parent process, and the latency is measured on the other CPUS. This was run 100 times. Then a variant which did an insmod system call on CPU 0 was used (this calls stop_machine, which is what we were trying to measure).
The results are interesting and a little surprising. Normal max latency is around 35 usec, the stop_machine increasing it to the 100 range. There's obviously something running periodically on CPU 2: for both runs I had to remove one horrific 150ms latency result (1000 times average!) but there's still a noticeable spike there. I suspect CPU1 is low because CPU0 is mainly idle (same core).
But more concerning is that latency seems to go up with higher CPU numbers, whereas I expected it to be worst on lower CPUs. We launch stop_machine threads in cpu order, so I expected the lower CPUs to wait the longest.
We're running modprobe on cpu 0, which means the stop_machine control thread runs there, too. It loops through creating 17 other threads: as CPU 0 is busy, it gets scheduled on a different idle CPU. The first thing the thread does is try to move itself to its proper CPU.
I suspect what is happening is that we're creating the 17 threads fast enough that they all end up queued on the migration queue for CPU 0 at once: this queueing uses "list_add" not "list_add_tail", so they are in fact deployed by the migration thread in reverse-CPU order.
My simplified version of stop_machine is more intelligent: it moves all the threads to their correct CPUs before waking them all up. This should solve this problem as well as reducing overall latency.
[/tech] permanent link
Fri, 16 May 2008
Tuning VirtIO and virtio_net: part I
One premise of virtio is that we should be as fast as reasonably possible. While there's nothing which should make us slow, that's not the same as actually being fast. So this week, I've been doing some simple benchmarks on my patch queue, which includes major changes to accelerate the tap device and allow async packet sends.
I've been using lguest rather than kvm because it's far more hackable, and my test has been a 1GB (1024x1024x1024 byte) TCP send using netcat. And host->guest results were awful: instead of the current 12 seconds it was taking 70 seconds to receive 1GB. So I started breaking that down.
The first things that I found was that simply allocating large receive buffers (of which only 1500 bytes is used) is expensive. Just this change alone takes the time from 12 seconds to 29, and there are two reasons for this so far.
The first is because each 1500 byte packet takes two descriptors (we have a header containing metadata), whereas a fully populated paged skb takes 2 + 65536/PAGE_SIZE + 2 == 20 descriptors. That means we only fit 6 large packets in lguest's 128-descriptor ring, vs 64 for the small packet case. Increasing lguest's rings to 1024 drops the time from 29 to 25: not as much as you'd expect. Increasing it further has marginal effect (logically, we should see equivalence at 1280 descriptors, but it has to be a power of 2).
The second reason is that alloc_page is quite slow. A simple cache of allocated pages drops the time from 25 to 19 seconds.
But we're still 50% slower than allocating 1500-byte receive buffers, and today's task is to figure out why. It seems unlikely that the increased overhead of skb_to_sgvec, get_buf and add_buf would account for it. Cache effects also seem unlikely: 1024 descriptors are still only 8k. It's unfortunate that oprofile doesn't work inside lguest guests, so this will be old school.
If the overhead really is inherent in large descriptors, we have several options. The obvious one is to add a separate "large buffer" queue, or allow mixing buffer sizes and expect the other end to try to forage for the minimal sized one. Both require a change to the server side. We can add a feature bit for backwards-compat, but that's always a last resort. Another option is to try for multi-page allocations for our skbs: as they're physically contiguous they'll use fewer descriptors.
[/tech] permanent link
Tue, 22 Apr 2008
Austin, TX
Arrived for the virtualization mini-summit (alongside the Linux Foundation Collaboration Summit) the week before last, and stayed around because much of IBM's kvm work is done here. Much hacking, but I should have blogged about my travel plans sooner.
I leave on Friday for San Jose (on the "Nerd bird" I'm told) for the weekend before I fly back home, but if anyone wants to catch up, send mail...
[/self] permanent link
Mon, 07 Apr 2008
C inline functions not in headers
I just appreciated an interesting side-effect of slapping "inline" on static functions within .c files. You don't get a warning when they become unused.
This breaks my normal method for code cleanup (in this case, the tun driver). So unless you have evidence otherwise, plase trust the compiler to inline static functions appropriately and don't label them inline. (And remember: inline is the register keyword for the 21st century.)
[/tech] permanent link
Sat, 05 Apr 2008
Hard To Misuse Commentry
[/tech] permanent link
Tue, 01 Apr 2008
What If I Don't Actually Like My Users?
Here begins our descent into hell; if an interface manages to achieve negative scores on the Hard To Misuse List, your users may detect the dull red glow of malignancy rather than incompetence.
- -1. Read the mailing list thread and you'll get it wrong.
-
If the first hit on Google when searching for the symptoms or how to use your interface leads to a convincing but incorrect answer, that puts your interface here.
- -2. Read the implementation and you'll get it wrong.
-
This happens most often when the implementation being read is not the one you which ends up being used. Or maybe the implementation comes with test cases which all exercise the unnatural corners of the interface, which mislead instead of enlightening.
- -3. Read the documentation and you'll get it wrong.
-
Here's my favorite (now fixed) example, from the glibc snprintf man page:
RETURN VALUE snprintf and vsnprintf do not write more than size bytes (including the trailing '\0'), and return -1 if the output was truncated due to this limit.I was scanning the man page for the return value on overlength snprintfs; now I'd found it I stopped reading. But here was the next sentence:
(Thus until glibc 2.0.6. Since glibc 2.1 these functions follow the C99 standard and return the number of characters (exclud- ing the trailing '\0') which would have been written to the final string if enough space had been available.) - -4. Follow common convention and you'll get it wrong.
-
The usual example here is fputs() and similar which take the context argument at the end instead of the start:
int fputs(const char *s, FILE *stream);
But that doesn't quite get down here: the compiler will warn if you get the argument order backwards (or, if you prefer, forwards). So again I reach to the Linux Kernel, this time for the list macros:
void list_add(struct list_head *new, struct list_head *head);
I now have this nailed into my brain, but for a long time I expected the 'head' (ie. the list I'm adding to) to be the first argument. Of course, this wouldn't be such a problem if list heads and list entries were not exactly the same type.
- -5. Do it right and it will sometimes break at runtime.
-
Every C programmer knows that malloc returns NULL on error:
p = malloc(bufsize); if (!p) { /* Phew! We can handle this... */ backout_nicely(); exit(1); }Except malloc may also return NULL on zero-length allocations: something you'll find out the hard way when your nice code which didn't special case 0-length allocations breaks horribly on someone else's machine.
- -6. The name tells you how not to use it.
-
Sometimes we opt for changing behavior without changing a (now-inappropriate) name, knowing that existing users won't be broken by the new behaviour. But don't curse future users with a misleading name: if your project takes off, there will be far more of them than current users.
My example here is another Linux kernel one which bit me. I was writing a block (disk) driver: it gets passed a struct request which consists of a series of chunks. After servicing them, it calls end_request(). Only it turns out that (for historical reasons!) this only ends the first chunk. My block driver "worked", but it was doing about N^2/2 times the work it needed to do for an N-chunk request.
(I didn't find that, the maintainer reviewing my code did).
- -7. The obvious use is wrong.
-
I've been coding in C for about 20 years, and about five years ago I spent an hour chasing a case where I'd done if (strcmp(arg, "foo")) instead of if (!strcmp(arg, "foo")). Now I religiously #define streq(a, b) (!strcmp((a),(b))) because I know I'm not as smart as I think I am.
Less "I'm obviously an idiot" is the behavior of strncpy() which truncates the destination string without adding a NUL terminator. Or char x[5] = "hello"; which the C standards committee thought would be an excellent trap for newcomers (and particularly stupid since there is a workaround if you really want an unterminated character array).
- -8. The compiler will warn if you get it right.
-
The bind() socket library call comes to mind here: it takes a struct sockaddr but you always have to cast to use it, as you will never have a struct sockaddr, but instead a struct sockaddr_in or some other specific type. This one is almost excusable, although I'd expect better from modern code.
- -9. The compiler/linker won't let you get it right.
-
This is hard to find in C, since the compiler will let you cast your way through almost anything. Listed here for completeness.
- -10. It's impossible to get right.
-
Unlike the first category, this final category is neither a paragon nor unattainable. Some interfaces are so fundamentally flawed that they can't be used correctly. Perhaps it can fail in a way you have to know about but it doesn't return an error. Perhaps it returns an error but you can do nothing about it.
In the Linux kernel there used to be interfaces which assumed single-threading, and are now unsafe. Say you expose two functions called prepare() and and action() and expect the caller to do if (prepare()) action();. This is broken if action() relied on all the checks in prepare() passing, and now conditions can change between the two.
That's everything I know about interface design. Now, go and make your own mistakes so you can have wise things to say about it!
[/tech] permanent link
Sun, 30 Mar 2008
How Do I Make This Hard to Misuse?
It's useful to arm ourselves with a pithy phrase should we ever have to face an "it'll be easier to use!" argument. But once we've pointed to it, it's still not clear how to improve the difficulty of interface misuse.
So I've created a "best" to "worst" list: my hope is that by putting "hard to misuse" on one axis in our mental graphs, we can at least make informed decisions about tradeoffs like "hard to misuse" vs "optimal".
The Hard To Misuse Positive Score List
- 10. It's impossible to get wrong.
-
This ideal is represented by the dwim() (Do What I Mean) function, where misuse means the implementation has a bug. In real life this goal is only achievable by greatly restricting your definition of misuse. Even the dwim() function can be abused by not calling it at all.
- 9. The compiler/linker won't let you get it wrong.
-
As a C person, I like that the compiler reads all my code before it even gives me a chance to run any of it. We're so used to this we don't give it a second thought when the compiler barfs because we use the wrong type or don't provide enough arguments to a function. But we can go out of our way to use this: various project such as gcc and the Linux kernel have macros like BUILD_BUG_ON(cond) which can be implanted strategically to evoke compile errors (it evalates sizeof(char[1-2*!!(cond)]) which won't compile if cond is true).
I use this in the kernel's module_param(name, type, perm) macro to check that the read/write permissions for the module parameter are sane (a common mistake was to specify 644 instead of 0644).
- 8. The compiler will warn if you get it wrong.
-
This is weaker than breaking the compile, but in many cases easier to achieve. The classic of this school is the Linux kernel min() and max() macros, which use two GCC extensions: a statement expression which allows the whole statement to be treated by the caller as a single expression, and typeof which lets us declare a temporary variable of same type as another:
/* * min()/max() macros that also do * strict type-checking.. See the * "unnecessary" pointer comparison. */ #define min(x,y) ({ \ typeof(x) _x = (x); \ typeof(y) _y = (y); \ (void) (&_x == &_y); \ _x < _y ? _x : _y; })Since a common error in C is to compare signed vs unsigned types and expect a signed result, this macro insists that both types be identical.
- 7. The obvious use is (probably) the correct one.
-
Always make it easier to do the Right Thing than the Wrong Thing. So if you can't make the right thing easy, make the wrong thing hard! This is the "explicit args required for kmalloc" example again, but it usually means choosing defaults carefully and knowing the normal use for the function.
My example here is the standard Unix exit() and _exit(): the latter does not call any atexit() handlers and is usually not the right choice, so it's harder to find.
- 6. The name tells you how to use it.
-
Everyone knows a good name is invaluable. In the _exit() the underscore punches far above its one-character weight was a warning sign.
My example here is the strange reference counting mechanism used by the Linux Kernel module code: getting a reference count can fail, unlike almost all the rest of the kernel reference counts. Hence, the "get a reference count" function is called try_module_get(): those first four characters reflect the importance of the return code. Note that these days, the GCC "__attribute__((warn_unused_result))" can be used to promote this usage to a warning. I still like the name, though, because overuse of such things has lead to some warning fatigue...
- 5. Do it right or it will always break at runtime.
-
As soon as the misusing code is executed, it'll die horribly. Not all code paths are tested, but this will often catch cases where someone is writing new code using your interface. It's hard for the compiler to ensure that the user calls your "open" routine before your other routines, but an "assert()" can at least get you to this level.
- 4. Follow common convention and you'll get it right.
-
This is a corollary of "this simplest use is the correct one", and a very useful handhold on the way up this scale. In particular, C convention for argument order seems to have evolved down to three ordered rules:
- Context argument(s) go first. A context is something the user will do a series of different things to; a handle.
- Associated arguments are adjacent. An array and its length go together, as does a timestamp and its granularity. If you could see yourself making a structure out of some of the args, they should go together.
- Details go as late as possible. Flags for the function go at the end. Pointer and length pairs are passed in that order.
I've never gotten the argument order of the standard write() wrong, even though the fd and count could be interchanged:ssize_t write(int fd, const void *buf, size_t count);
There are also minor (but important!) conventions, such as memcpy's "destination before source", which you should use for any memcpy-like routines.
Like all rules, this one exists to be violated; but know you're doing so.
- 3. Read the documentation and you'll get it right.
-
People only read instructions after they've already tied themselves into a knot. Then they skim them for keywords and don't read your warnings. I don't give an example of this; if this is the best an interface can get do, it's in trouble.
- 2. Read the implementation and you'll get it right.
-
We've all done this. Reading the implementation can work for the simple questions (what unit is this argument in?), but leads to trouble for the subtler issues. The concept of "the" implementation is always problematic, and when the implementation is tightened or fixed we discover we didn't actually get it right, we just got it working.
In some cases, the implementation is a noop, which doesn't help.
- 1. Read the correct mailing list thread and you'll get it right.
-
The reason the some strange interface quirk exists might be for compatibility with some strange OS or compiler, weird corner case or even older versions of this codebase. In other words, historical reasons ("see, on the VAX we only had 6 characters for..."). You sometimes only find this when you send a patch to fix it and the original author yells at you.
Sometimes they add it to the FAQ. That does not increase the interface's score very much: please try harder.
[/tech] permanent link
Tue, 18 Mar 2008
APIs: "Easy to Use" vs "Hard to Misuse"
It's an elementary goal of API design to make something easy to use: easy for yourself, easy for yourself next year, easy for others. Let's take that as a given.
Many goals will conflict with "easy to use", but the subtlest is the requirement that an API be hard to misuse. Ease of use attracts users, but difficulty of misuse keeps them alive.
To make this concept crisp, I have two real life examples. The first is the safety catch on a gun. Hard to misuse beats easy to use.
The second example is the Linux kernel's kmalloc dynamic memory allocation function. It takes two arguments: a size and a flag. The most commonly used flag arguments are GFP_KERNEL and GFP_ATOMIC: I'll ignore the others for this example.
This flag indicates what the allocator should do when no memory is immediately available: should it wait (sleep) while memory is freed or swapped out (GFP_KERNEL), or should it return NULL immediately (GFP_ATOMIC). And this flag is entirely redundant: kmalloc() itself can figure out whether it is able to sleep or not. Implementing malloc() would be a no-brainer, and kernel coders generally like ease of use. So why don't we? [Correction:Jon Corbet points out that it's not entirely redundant in some configurations; we'd need to do a few lines extra work.]
Because atomic allocations should be avoided: they're drawing from a limited pool and more likely to fail or make other atomic allocations fail. By placing the burden of specifying this onto the author, we make atomic allocations easier to spot and thus harder to abuse.
And if we want to make our APIs harder to misuse we need to measure how an API scores, and that'll be the topic of the next post.
[/tech] permanent link
Wed, 12 Mar 2008
Bricklayer, not cathedral builder.
I'm always a little uncomfortable with "fuzzy" programming topics; much better to judge between two specific pieces of code. The big issues are important but it's hard to say something new on that topic which will help people code better. Most useful stuff has been said already.
Nonetheless, for my OLS keynote years ago I did have a point which I felt was underappreciated, and managed to rope it down to actual guidelines so the idea was of practical use. I'm going to revisit that topic in my next few blog posts, because unfortunately my OLS keynote was not recorded anywhere for me to simply point to, and there has been some maturing of these ideas since then.
[/tech] permanent link
Thu, 28 Feb 2008
Holidays, no mail, chilling.
So I've taken February off, and after Wed 6th I realized that I couldn't do that and still read my email. So I shut my laptop for three weeks and just hung out around the farm.
I've read a half-dozen or so books, cut up lots of firewood for winter, visited the Big Hole, organized a small expedition into the nearby Wyanbene Caves, kept track of my in laws' late nights playing Zelda: Twilight Princess on their new Wii, picked blackberries with various guests and done a heap of chores.

[/self] permanent link
Wed, 06 Feb 2008
lca2008 Projector Pong with Wiimote and Linux: Pong Hero!
Once the teething problems were out, and with much assistance from various people, we had fun at linux.conf.au's Open Day playing a pong variant using IR pens and a Wiimote.
I've finally put all the information up on a typically-ugly web page, including a link to the source code.
[/tech] permanent link
Wed, 30 Jan 2008
lca2008: 70 OLPCs Randomly Seeded Among Attendees
For years it has been an LCA dream to put an OLPC in every attendee's registration bag, to give the project a development boost and inspire our attendees. We didn't quite get there, but we did get 100.
Jim Gettys and I announced at the keynote that we had a handful available, and we'd chosen names a random. We gave out 10 there, and leaked out another 60 to random people over the morning.
I fought hard for randomness, because we don't know who will make best use of them and I trust our attendees to pass them on if they can't do something wonderful. Some comments overheard since then have battered my faith, but I still hope that most people will make sure these XOs make a difference.
BTW, the following people were loved by the random number generator but still haven't been found (send them to Registration Desk):
- Geoff O'Callaghan
- Peter Karlsson
- Brinley Craig
- Bill Robertson
- Stacy Gillett
- Nicholas Nethercote
- Techfatt Wong
- Tim Josling
[/tech] permanent link
lguest lca2008 Tutorial Preparation Fastpath
- Get a 2.6.23 kernel
- Make sure CONFIG_EXT2=y so you can read the root image.
- Build your kernel with CONFIG_LGUEST=m (here are pre-built kernel trees for Debian unstable and Ubuntu 7.10 (Gutsy).)
- Install the kernel on your machine.
- cd into Documentation/lguest/ and type "make" to build the "lguest" launcher binary (you will need the zlib headers and static libraries).
- Grab a simple root image I use the Xen-test tiny image.
- Reboot into your 2.6.23 image.
- sudo modprobe lg
- Run the lguest launcher like so:
sudo /usr/src/linux-2.6.23/Documentation/lguest/lguest --block=initrd-1.1-i386.img 128 /boot/vmlinuz-2.6.23.14 root=/dev/lgba
- If you see the "sh" prompt, you're ready for the tutorial!
There's also a Qemu image with instructions but you need to build outside and install updates into the image.
[/tech] permanent link
Sat, 26 Jan 2008
linux.conf.au 2008 lguest tutorial: Preparation!
For the lguest tutorial, you will need lguest working. This is a hacking tutorial. This means a 2.6.23 kernel (lguest is different in 2.6.24, so 2.6.23 please!) with lguest support. Sorry, 32-bit x86 only.
I'm serious: I'll be turning people away who don't have lguest booting already. Fortunately, we have a BOF from 12:30-2:30 on the Wednesday (that's lunchtime and the next session) to help people get setup.
[/tech] permanent link
Tue, 15 Jan 2008
sg_ring: Sorry, -ETIMEDOUT
Beyond a quickly-reached line, arguing with the maintainer is not a path to getting your patches accepted. Let me just say that I'm in the DaveM school of "then we'll simply rewrite all the drivers" rather than the James Bottomley "abstractions make us futureproof" school.
[/tech] permanent link
Wed, 09 Jan 2008
Partial checksumming of virtio net packets
Today I started hacking on adding extensions to the tun/tap driver; I was going to try adding async I/O but that seems to be a major reenginering and not likely to get in while syslets are waiting in the wings (so meanwhile just use a thread).
Partial checksumming and GSO support are my aims: virtio_net supports both at the moment but both kvm and lguest don't turn on those feature bits becasue tap doesn't support them.
This afternoon partial checksumming. Implemented, added some printks to make sure it was happening, and then started doing sendfile benchmarks (160MB guest to host). And the differences were marginal. David Miller pointed this out long ago: if you're copying the data with the CPU (as tap does), the checksumming calculation is in the noise.
So tomorrow is GSO support, and using get_user_pages() to avoid copying the skb (except some amount of header). Then it should be a real win...
The beautiful thing: I've made the GSO-describing header for the tap device suspiciously identical to the header for the virtio_net device, so the lguest launcher just passes the whole thing through.
[/tech] permanent link
Tue, 08 Jan 2008
Yak Shaving, eventfd and libaio
Anthony Liguori pointed out that one performance bottleneck for kvm (and lguest, if we cared) is the fact that the tap device doesn't support AIO.
Of course I said, AIO is evil because it's incompatible with poll(), to which he replied "eventfd". This was a introduced in 2.6.21 and AFAICT is best documented in the commit message. Two patches later Davide slipped in AIO support so AIO requests can hit the eventfd.
So now I want to use the thing, and I track down libaio: shipped by Ubuntu, SuSE and RedHat, and referred to by the io_submit(2) man page. Unfortunately, it's out-of-date: looks no eventfd support. In fact, at I can't find any version beyond 0.3.92 (Ubuntu claims 0.3.106) from 2002: looks pretty unloved.
Ok, let's update the header, and then I decide to run the test suite to make sure I've not broken anything. The test suite doesn't compile; maybe it did with older gccs and glibcs, but not any more. Hack it for the moment and run the tests.
Wade through the errors. Find two kernel bugs, create patches and send them off (corner cases, yes, but this is a bad sign). Find a couple of errors in the testsuite. Fix up the Makefile with a "make check" to do all the stuff the README says to do manually. Three or four hours later, send off patch.
Ben LaHaise hasn't responded directly, don't know if he's still interested in maintaining libaio (he indicated he's going to handover the kernel side). So for posterity (and others searching for preadv/pwritev or eventfd support for libio): here's my patch.
[Update: Jeff Moyer is keeping a repo with updates:
cvs -d :pserver:anonymous@rhlinux.redhat.com:/usr/local/CVS login # no password
cvs -d :pserver:anonymous@rhlinux.redhat.com:/usr/local/CVS co libaio
Currently this is on the branch jmoyer-work-branch]
Now, what was it that I supposed to be doing?
[/tech] permanent link
Mon, 07 Jan 2008
My first git whine for 2008
I don't like to whinge about software; that's what bug reporting is for. But it might be instructive to see how I spent the last 20 minutes.
Went to clone my copy of the kvm repo onto my Ubuntu test machine (debussy). Decided to clone my linux-2.6 tree first: might as well have it there. After installing git, then realizing my mistake, removing it and installing git-core, I was ready.
First I rsync'ed the linux-2.6 tree from my laptop, but then:
rusty@debussy:~$ git clone --reference=linux-2.6 git://git.kernel.org/pub/scm/linux/kernel/git/avi/kvm.git error: object directory /home/rusty/devel/cvs/kvm/kvm.git/kvm/.git/objects does not exist; check .git/objects/info/alternates. error: refs/reference-tmp/refs/remotes/origin/HEAD points nowhere! ...
Clearly, I'd made my laptop linux-2.6 tree with references to my laptop kvm tree (saving bandwidth and disk space). OK, my bad. I should use 'git clone' to do the transfer rather than rsync.
First attempt was dumb: 'git clone linux-2.6 debussy:' took a while, and only when I looked on debussy did I realize I'd just cloned into a 'debussy:' dir on my laptop. OK, proper url:
rusty@vivaldi:~/devel/kernel$ git clone linux-2.6 ssh://debussy/ Initialized empty Git repository in /home/rusty/devel/kernel/ssh:/debussy/.git/ remote: Generating pack...
Err, OK, clone doesn't understand destination URLs. Remove the 'ssh:' dir it just created, ssh into debussy and try to clone from there:
rusty@debussy:~$ git clone ssh://192.168.5.3/devel/kernel/linux-2.6 rusty@192.168.5.3's password: fatal: '/devel/kernel/linux-2.6': unable to chdir or not a git archive fatal: unexpected EOF fetch-pack from 'ssh://192.168.5.3/devel/kernel/linux-2.6' failed.
Err, that's not the dir I asked for. OK, use full pathname:
rusty@debussy:~$ git clone ssh://192.168.5.3/home/rusty/devel/kernel/linux-2.6 rusty@192.168.5.3's password: Connection closed by 192.168.5.3 fatal: unexpected EOF fetch-pack from 'ssh://192.168.5.3/home/rusty/devel/kernel/linux-2.6' failed.
Um, what happened there? No idea. So, I go back to my laptop to create a "clean" dir with no references, so I can just use rsync.
rusty@vivaldi:~/devel/kernel$ rm -rf tmp; git clone linux-2.6 tmp ... rusty@vivaldi:~/devel/kernel$ rsync -avz tmp debussy:linux-2.6 ... rusty@vivaldi:~/devel/kernel$ rm -rf tmp
Back to debussy:
git clone --reference=linux-2.6 git://git.kernel.org/pub/scm/linux/kernel/git/avi/kvm.git tar: refs: Cannot stat: No such file or directory tar: Error exit delayed from previous errors error: object directory /home/rusty/linux-2.6/objects does not exist; check .git/objects/info/alternates. remote: Generating pack... remote: Counting objects: 6651 ^C
Poke around: I forgot the / in rsync, so it's created a linux-2.6/tmp dir. Git spat some cryptic complaints (not "that's not a git repo"), then seemed ready to pull everything (precisely what I try to avoid on my 3G-per-month satellite connection). OK, move that dir up one...
git clone --reference=linux-2.6 git://git.kernel.org/pub/scm/linux/kernel/git/avi/kvm.git error: refs/reference-tmp/refs/remotes/origin/HEAD points nowhere! ...
No idea what that error is, so I'm ignoring it. Git seems to. And after all that, what directory does git create? Not "kvm.git", but "kvm", which appeared nowhere on that commandline. Confusing, because I had an old kvm.git dir there, too...
You can see I'm no git poweruser, and inevitably git will get easier as I memorize the various arcana. But for Rusty today, git is the slowest of the modern version control systems. And that's not counting the time it takes to blog out my frustrations after using it... :)
[/tech] permanent link
Fri, 04 Jan 2008
#ifdef and -Wundef
One of the problems with the C preprocessor is that it deals with undefined symbols by treating them as 0, which can hide bugs. A subtler problem is the widespread use of #ifdef: if you make a typo or use an obsolete name, you don't get any warning.
Fortunately, gcc has -Wundef, which warns about any undefined preprocessor symbols. But to use it to its full effect, you need to change the common C idiom of ifdefs. Instead of this:
/* Define HAVE_FOO if you have foo support. */ #ifdef HAVE_FOO ... #endif
You need to start doing this:
/* Define HAVE_FOO to 1 if you have foo support, otherwise 0. */ #if HAVE_FOO ... #endif
The fact that the Linux kernel uses #ifdefs instead of #if and -Wundef is one of those warts which would be nice to fix if we were starting over, but not worth the churn for such an established project. New projects however...
[/tech] permanent link
Wed, 02 Jan 2008
Chained scatterlists vs. sg_ring
Ever since Jens Axboe's scatterlist chaining patches intruded on my consciousness, they made me uncomfortable. The overloading of lower bits to allow chaining isn't what bothered me, it was how nasty they are to manage: chaining requires an extra padding element, and so you can't do much manipulation with a chained sg handed to you by someone else. This bit the virtio code when I tried to use them.
This, I decided, was one of those places where neat tricks should give way to explicitness: having an exposed two-level structure is easier to understand, debug and manipulate. It also means that new code (struct sg_ring *) is obviously different from unconverted code (struct scatterlist *).
However, when you actually try to do this, you're faced with modifying all the SCSI drivers. Not in a significant way, but changing loops to use different iterators. And after a number of days over the break spend touching those drivers, I understand why Jens chose the approach which placed so little burden on them (even if annoying for everyone else).
It's because these drivers are horrible. Really bad. Clear bugs, non-obvious assumptions and years of neglect. It's certain that converting them in one hit is not feasible, and perhaps any conversion indicates temerity. So at the least, a long-term conversion path is necessary.
[/tech] permanent link
